Optimizing Transformations in Pentaho: Case Study

In my current role as an IT Analyst, I was tasked with verifying and correcting an automatic transformation in Pentaho.
Pentaho is a suite of business intelligence (BI) tools that enables companies to collect, integrate, visualize, and analyze data from various sources to make informed decisions. It offers a range of functionalities, including data integration, interactive and dynamic reporting, data analysis, dashboard creation and management, data mining, Big Data, among others.
The Challenge
The transformation I had to analyze and optimize consists of extracting data some databases and then inserting them into a single table in another specific database. At first glance, everything seems logical. However, the original workflow presented a critical problem:
- Query in three different databases.
- Deletion of all data from the target table.
- Insertion of data from the three previous queries into the target table.
This approach may seem reasonable, but it becomes problematic as the volume of data increases. Performing a DROP TABLE on every transformation execution (several times a day) can greatly impact the performance of a production database, especially if the table is used as a reference in crucial daily operations.
The Solution
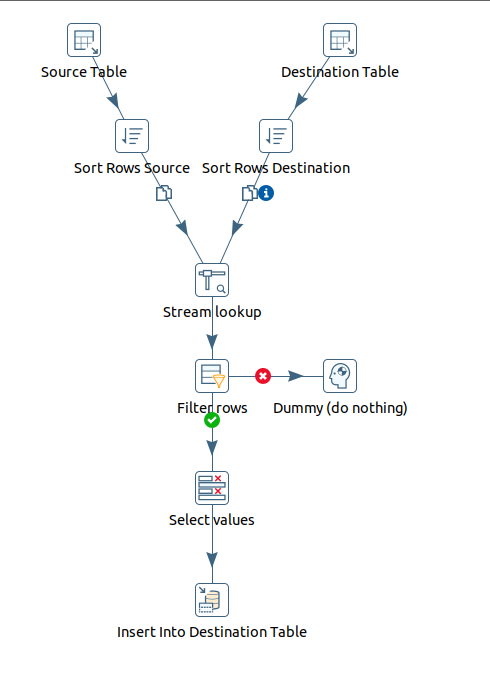
To solve this problem, I restructured the transformation flow. The original flow was: SELECT -> INSERT. I modified it as follows:
- Select source table: A data selection is performed from the source table.
- Select target table: A data selection is performed from the target table.
- Sort rows: The rows obtained from the source table are sorted.
- Sort rows 2: The rows obtained from the target table are sorted.
- Stream lookup: A data lookup is performed between the two previously sorted sources (source and target). This step combines rows from both sources based on some common key, adding the key field of the source table with that of the target table.
- Filter rows: The rows resulting from the Stream lookup step are filtered. Depending on the specified condition, the rows will be split into two streams. This step filters out the records that are already inserted and those that are not (NULL).
- If they meet the condition (key field set to null), they will move on to the Select values step.
- If they do not meet the condition, they will move on to the Dummy (do nothing) step.
- Dummy (do nothing): This step does not perform any operation; it is a holding place for rows that do not meet the filter condition.
- Select values: Specific values are selected from the rows that met the filter condition.
- Insert into target table: The selected values are inserted into the target table.
This procedure ensures that only missing records are inserted into the target table, thus avoiding the need to do an unnecessary DROP on a production database table, which is used by various database processes (procedures, triggers, functions, etc.) in order to provide good service to customers and avoid negatively affecting the business.
Record Keeping
Also, what happens when you need to delete existing records in the target table that are no longer in the source table? The flow is similar to the one mentioned above, except that in step 5 the key field to compare in reverse is added and the last step is changed to a DELETE instead of an INSERT.
Conclusion
This optimization not only improves the performance and efficiency of the production database, but also ensures data integrity and system stability. It is a clear example of how a small modification in approach can have a significant impact on the performance and reliability of IT systems.